
マルチモーダルAIが拓く未来の可能性 社会を変える新時代の到来
1年前、AIと言えば、シングルモーダルAIが主流でした。
例えば、「ChatGPT」はテキストを入力してテキストを出力していましたし、「Midjourney」や「Stable Diffusion」はテキストを入力して画像を出力していました。他にも、音声データを読み込ませてテキストデータに変換させたり、映像データを分析させて人物を特定させたりしていました。これらはすべて、テキストや音声、映像といった単一のデータを入力し、AIで処理させているので、シングルモーダルAIとなります。
マルチモーダルAIは複数のモダリティ(様式)、つまり映像と音声、映像とテキストなどを同時に入力して処理できるのが特徴です。
例えば、現在では「ChatGPT」や「Gemini」といった生成AIには画像ファイルとテキストを同時にアップロードし、「この画像から得られる教訓はなんですか?」などと質問することができます。
もはや人間のようにコミュニケーションすることができるのです。そして、既にマルチモーダルに対応した生成AIソリューションが登場しています。今回は、テキストに加えて映像や音声も同時に扱うマルチモーダルAIの解説と、マルチモーダルAIが進化することで実現する驚くべき世界についてご紹介します。
 マルチモーダルAIはテキストや画像、動画、音声、センサーデータなど、異なるデータを扱います。データの前処理として、テキストをトークン化したり、画像をノイズ除去やサイズ調整を行った後に正規化したり、音声はスペクトログラムなどに変換します。その後、テキストデータからはトランスフォーマー技術により、単語の意味や文脈を抽出するのです。画像の場合は畳み込みニューラル ネットワーク (CNN)を利用して被写体の形や色などを抽出します。
マルチモーダルAIはテキストや画像、動画、音声、センサーデータなど、異なるデータを扱います。データの前処理として、テキストをトークン化したり、画像をノイズ除去やサイズ調整を行った後に正規化したり、音声はスペクトログラムなどに変換します。その後、テキストデータからはトランスフォーマー技術により、単語の意味や文脈を抽出するのです。画像の場合は畳み込みニューラル ネットワーク (CNN)を利用して被写体の形や色などを抽出します。
続いて、抽出した特徴量を異なるモダリティ(テキスト/画像/音声/数値など複数の種類のデータ)間で利用できるようにモデル化します。例えば、映像とテキストのペアを学習することで、共通の表現空間に特徴をマッピングするのです。空間内の距離が近ければ、データの類似性が高い、ということです。また、異なるモダリティの情報でも、近い位置にあるならば似た意味を持っているということになります。
マルチモーダルAIはシングルモーダルAIよりもできることが格段に増えます。例えば、監視カメラの映像で二人の人物が話している場合、シングルモーダルでは話していることしかわかりません。しかし、音声も扱えるマルチモーダルAIであれば普通に話しているのか、揉めているのかがわかります。問題が起きる前に警備員を派遣するといった対応を取ることが可能です。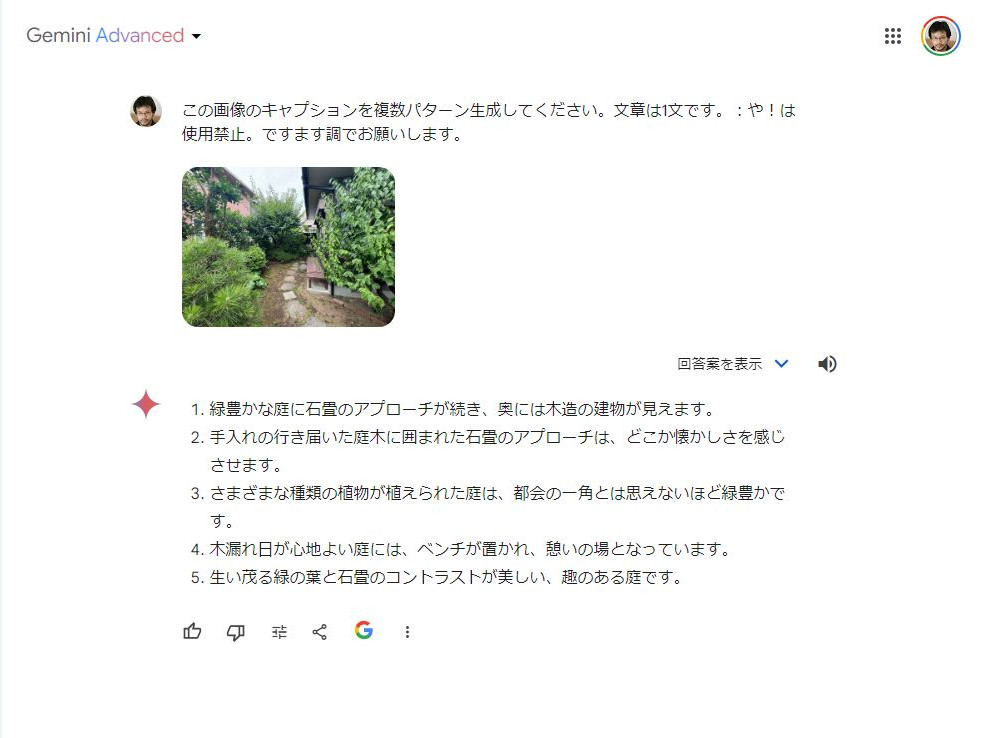 画像のキャプションをAIに考えてもらいました。
画像のキャプションをAIに考えてもらいました。
 看板を撮影して、内容を質問することができます。
看板を撮影して、内容を質問することができます。
 画像をアップロードして、異なる画風に変換できます。
画像をアップロードして、異なる画風に変換できます。
 ビジネスで本格的にマルチモーダルAIを活用する際は、「ChatGPT」のような汎用的な生成AIではなく、特化型のAIを開発することで精度を高めることができます。マルチモーダルAIが社会実装されるとどんな世界になるのでしょうか?
ビジネスで本格的にマルチモーダルAIを活用する際は、「ChatGPT」のような汎用的な生成AIではなく、特化型のAIを開発することで精度を高めることができます。マルチモーダルAIが社会実装されるとどんな世界になるのでしょうか?
設備の稼働音や振動のセンサーデータ、温度情報などを組み合わせて解析することで、設備の故障や異常を早期に察知できます。作業員の安全確保にも役立ちます。作業員の動作や周囲の状況、現場の音声情報を分析することで、危険を予測し、事故を未然に防ぐことができるようになるかもしれません。 マルチモーダルAIは異なるモダリティのデータを統合する難易度が高いことが課題です。データの品質やフォーマットが異なるので、一貫性を保つのが難しいのです。また、マルチモーダルデータにラベルを付けるのは人間なので、コストがかさむのもネックです。複雑なAIモデルになる分、当然、膨大な計算資源が必要になりますし、トレーニング時間も長くなります。
マルチモーダルAIは異なるモダリティのデータを統合する難易度が高いことが課題です。データの品質やフォーマットが異なるので、一貫性を保つのが難しいのです。また、マルチモーダルデータにラベルを付けるのは人間なので、コストがかさむのもネックです。複雑なAIモデルになる分、当然、膨大な計算資源が必要になりますし、トレーニング時間も長くなります。
しかし、マルチモーダルAIの可能性と社会的インパクトはとても大きく、確実に社会に広まっていくことでしょう。さらに、人間とコンピュータのコミュニケーションも大きく変化します。今までのような一問一答ではなく、人間との会話のように相手の表情を見ながら、リアルタイムに会話できるようになります。これは、将来と言うより、数か月以内に「ChatGPT」で実現することでしょう。
マルチモーダルAIにより、さらに大きく社会が変革します。変化に対応できる柔軟な思考を養い、AIスキルを身につけて新しい技術やサービスを活用していきましょう。
企業の内部データを有効活用する、個別企業向け生成AIサービスの破壊力とは
自己進化するAI アダプティブAIの重要性と活用領域
プロンプトエンジニアリングは難しい? 管理職こそAIを使いこなすべき理由とは

例えば、「ChatGPT」はテキストを入力してテキストを出力していましたし、「Midjourney」や「Stable Diffusion」はテキストを入力して画像を出力していました。他にも、音声データを読み込ませてテキストデータに変換させたり、映像データを分析させて人物を特定させたりしていました。これらはすべて、テキストや音声、映像といった単一のデータを入力し、AIで処理させているので、シングルモーダルAIとなります。
マルチモーダルAIは複数のモダリティ(様式)、つまり映像と音声、映像とテキストなどを同時に入力して処理できるのが特徴です。
例えば、現在では「ChatGPT」や「Gemini」といった生成AIには画像ファイルとテキストを同時にアップロードし、「この画像から得られる教訓はなんですか?」などと質問することができます。
もはや人間のようにコミュニケーションすることができるのです。そして、既にマルチモーダルに対応した生成AIソリューションが登場しています。今回は、テキストに加えて映像や音声も同時に扱うマルチモーダルAIの解説と、マルチモーダルAIが進化することで実現する驚くべき世界についてご紹介します。
マルチモーダルAIの原理と技術
続いて、抽出した特徴量を異なるモダリティ(テキスト/画像/音声/数値など複数の種類のデータ)間で利用できるようにモデル化します。例えば、映像とテキストのペアを学習することで、共通の表現空間に特徴をマッピングするのです。空間内の距離が近ければ、データの類似性が高い、ということです。また、異なるモダリティの情報でも、近い位置にあるならば似た意味を持っているということになります。
マルチモーダルAIはシングルモーダルAIよりもできることが格段に増えます。例えば、監視カメラの映像で二人の人物が話している場合、シングルモーダルでは話していることしかわかりません。しかし、音声も扱えるマルチモーダルAIであれば普通に話しているのか、揉めているのかがわかります。問題が起きる前に警備員を派遣するといった対応を取ることが可能です。
画像+テキストを渡して色々なことをさせてみる
Googleの生成AI「Gemini」はマルチモーダルAIです。「Gemini 1.5 Pro」に画像をアップロードし、いろいろと質問したり、指示してみましょう。何が映っていますか? などは余裕で回答してくるので、記事で使う画像に付けるキャプションを考えてもらいます。画像にキャプションを付けてもらう
画像をドラッグ&ドロップして、プロンプトに「この画像のキャプションを複数パターン生成してください。文章は1文です。:や!は使用禁止。ですます調でお願いします」と入力すると、5つの文章が生成されました。記事の内容などの前提条件をまったく入力していないのに、使えそうなキャプションになっていたのが驚きです。 画像のキャプションをAIに考えてもらいました。看板から情報を読み取ってもらう
「ChatGPT」の「GPT-4o」もマルチモーダルに対応しています。例えば、コインパーキングの料金が書かれている写真をアップロードして、利用時間を入れると、料金を教えてくれます。コインパーキングの料金システムは複雑なので、ありがたいところです。ただし、「ChatGPT」に限らず生成AIは計算ミスをよくするので、利用する際は自己責任でお願いします。看板を撮影して、内容を質問することができます。画像を生成してもらう
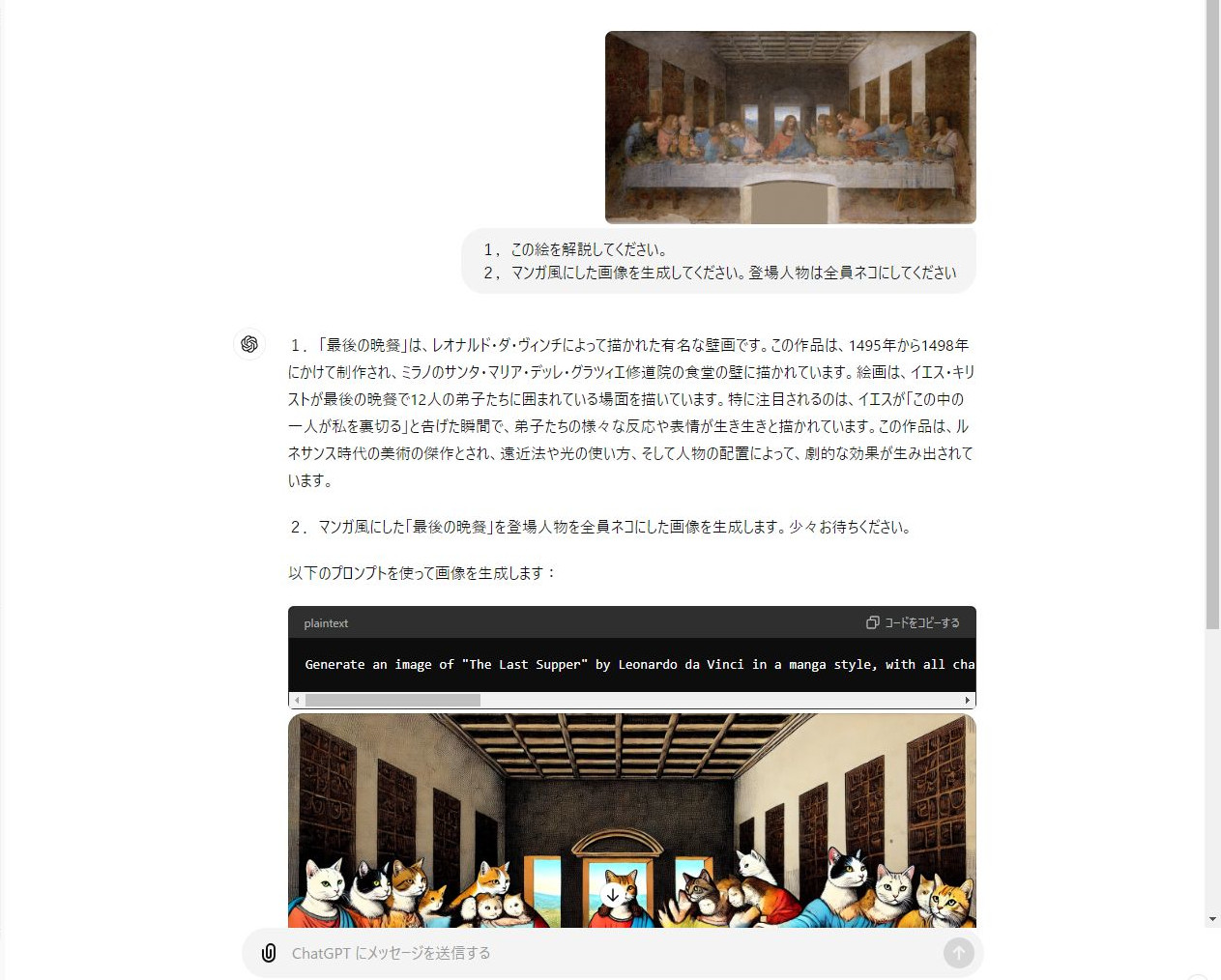
「ChatGPT」は画像を生成する機能も備えています。例えば、レオナルド・ダ・ヴィンチの「最後の晩餐」の画像をアップロードして、解説してもらうことはもちろん、登場人物を猫にしてマンガ風に描き直してもらうこともできます。 画像をアップロードして、異なる画風に変換できます。マルチモーダルAIで実現する便利で快適な世界
医療
まず期待されているのが医療分野です。X線やMRI、CTなどで撮影した画像と患者の電子カルテ情報や遺伝子情報をAIに渡すことで、正確に診断したり、治療方針の決定を支援したりできます。手術ロボットによる手術時には患者の様々なバイタル情報と手術器具の位置情報を統合的に解析し、手術の精度を向上させ、合併症リスクを低減できます。創薬
創薬の分野でも活躍します。2023年10月には、富士通と理化学研究所が生成AIを活用して大量の電子顕微鏡画像からタンパク質の構造変化を広範囲に予測する技術を発表しました。これまでは、長期の研究期間と多額の研究開発費用が必要でしたが、生成AIを活用することで10倍以上も速く構造変化を推定できるようになったのです。自動運転
数年前から注目されているのが車の自動運転です。地図情報に加えて、車載カメラやLiDARなどのセンサー、交通標識などを統合的にAIが解析し、自動運転を実現します。日本ではライドシェアも普及していませんが、現在、サンフランシスコでは完全無人の自動運転タクシーが一般開放されています。製造業
製造業でもマルチモーダルAIが使われています。製品を撮影し、エラーを検出する仕組みはこれまでもありましたが、マルチモーダルAIであれば各種センサーデータや製造履歴を組み合わせることで、不良品の検出精度を向上できます。設備の稼働音や振動のセンサーデータ、温度情報などを組み合わせて解析することで、設備の故障や異常を早期に察知できます。作業員の安全確保にも役立ちます。作業員の動作や周囲の状況、現場の音声情報を分析することで、危険を予測し、事故を未然に防ぐことができるようになるかもしれません。
小売業
小売業では、例えば店内カメラで検出した顧客情報から購買履歴などを参照してニーズを把握し、パーソナライズされた商品提案ができます。商品画像を認識し、重量やICタグなどのセンサーを組み合わせ、マルチモーダルAIを決済システムや在庫管理システムと連携させることで、無人店舗を効率的に運用できます。教育
教育分野では、学習内容に加えて、生徒の表情や発話している内容を分析し、個人個人の理解度や進捗をリアルタイムに把握し、パーソナライズされた学習プログラムを提供できます。生徒の興味や性格まで加味してカスタマイズした教材により、学習効率の向上も見込めます。防犯
もちろん、前述の監視用途でも普及することでしょう。防犯カメラの映像に加えて、音声情報やセンサーデータを組み合わせることで、不審者を検知し、犯罪を未然に防ぐことができるかもしれません。AIであれば、24時間365日、瞬きもせずに見守ってくれます。マルチモーダルAIの課題と未来
しかし、マルチモーダルAIの可能性と社会的インパクトはとても大きく、確実に社会に広まっていくことでしょう。さらに、人間とコンピュータのコミュニケーションも大きく変化します。今までのような一問一答ではなく、人間との会話のように相手の表情を見ながら、リアルタイムに会話できるようになります。これは、将来と言うより、数か月以内に「ChatGPT」で実現することでしょう。
マルチモーダルAIにより、さらに大きく社会が変革します。変化に対応できる柔軟な思考を養い、AIスキルを身につけて新しい技術やサービスを活用していきましょう。
著者:ITライター柳谷智宣
<関連コラム>企業の内部データを有効活用する、個別企業向け生成AIサービスの破壊力とは
自己進化するAI アダプティブAIの重要性と活用領域
プロンプトエンジニアリングは難しい? 管理職こそAIを使いこなすべき理由とは
ミツイワはあらゆるビジネスの課題をICTソリューションで解決します
ミツイワは1964年の創業以来、お客様のご要望に柔軟にお応えしながら、ICTシステム分野とデバイスソリューション分野の事業を進めてまいりました。
現在では、IoT、AI、ロボティクスなどデジタルソリューションも活用し、今までに無い問題の解決方法、そしてお客様に寄り添った質の高いサポートサービスで、お客様のビジネスの成長と安定を支援しています。